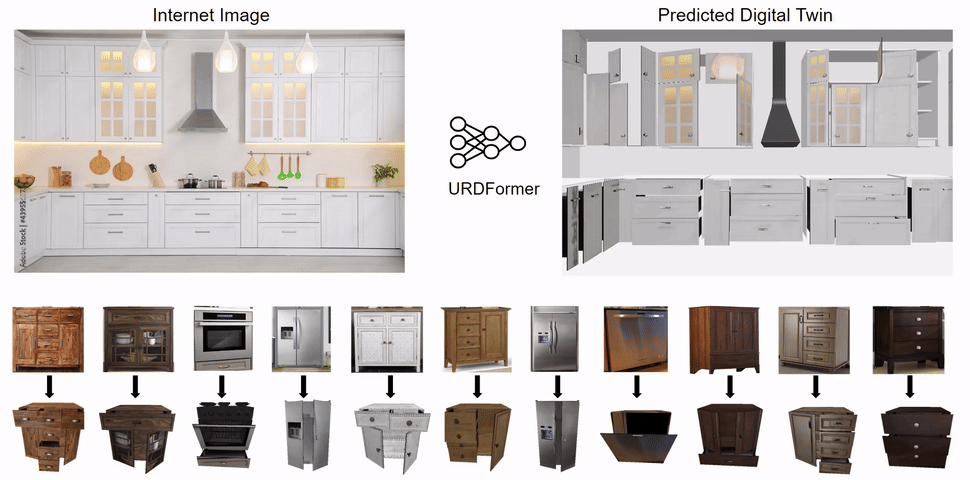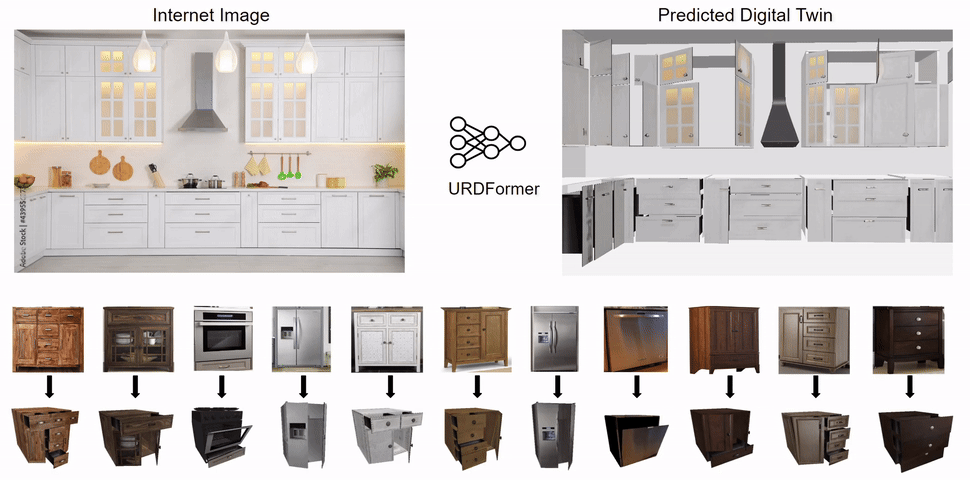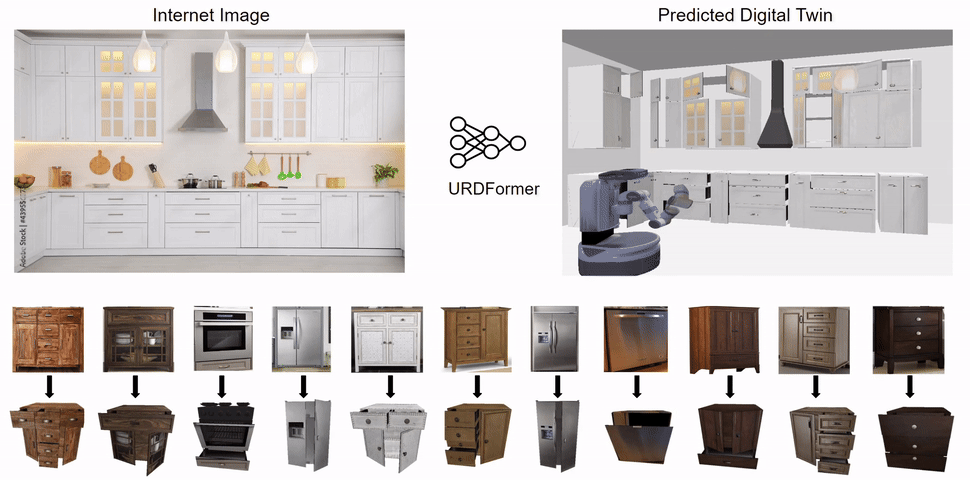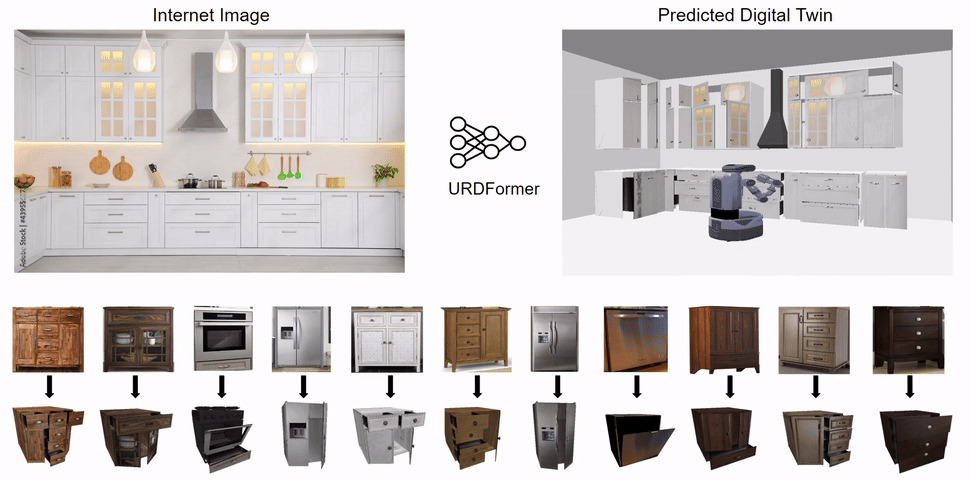
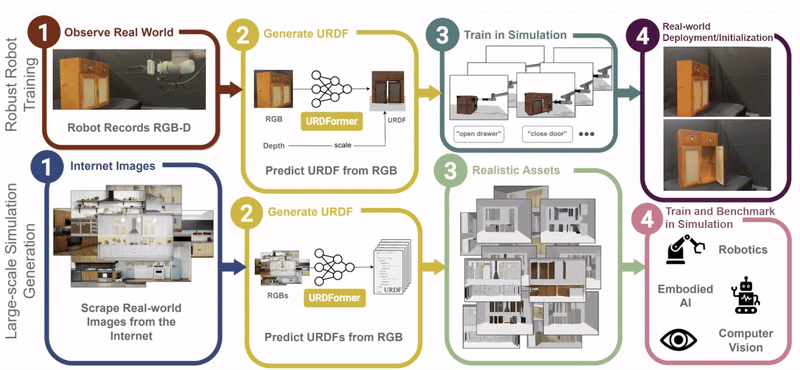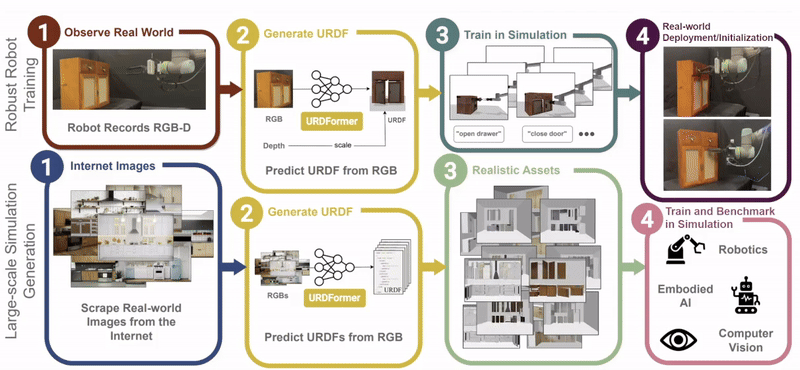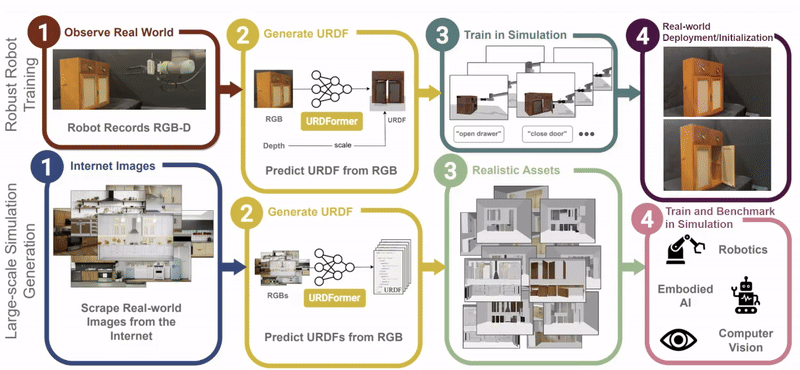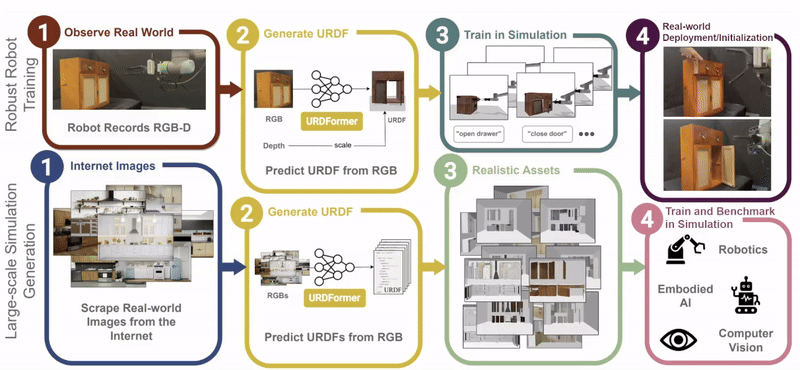
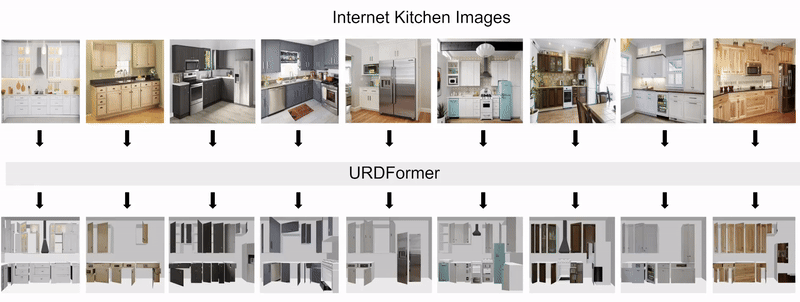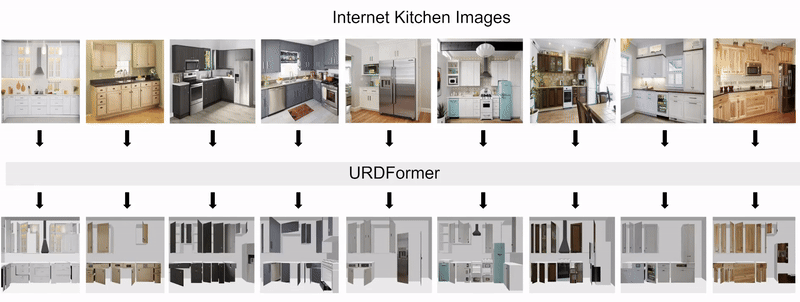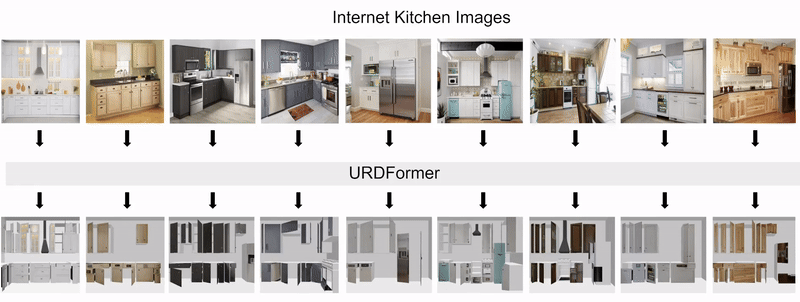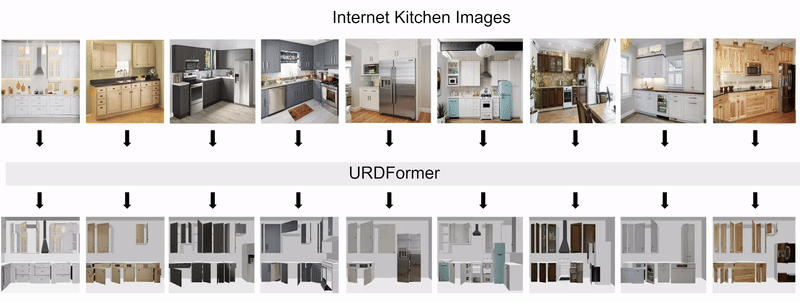
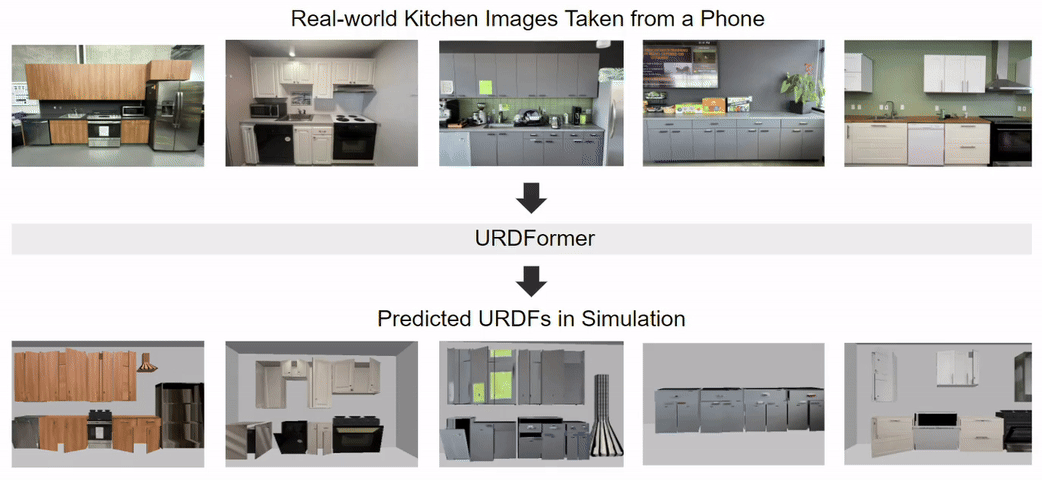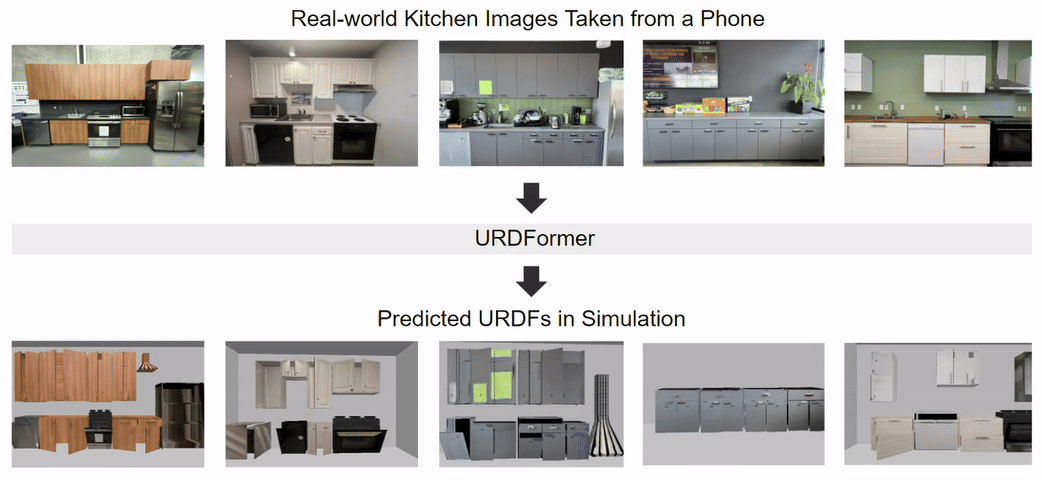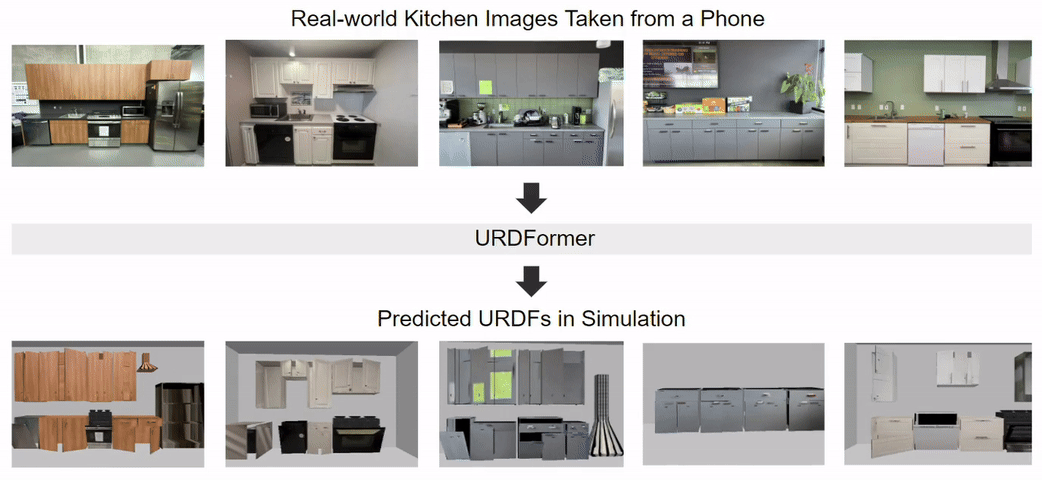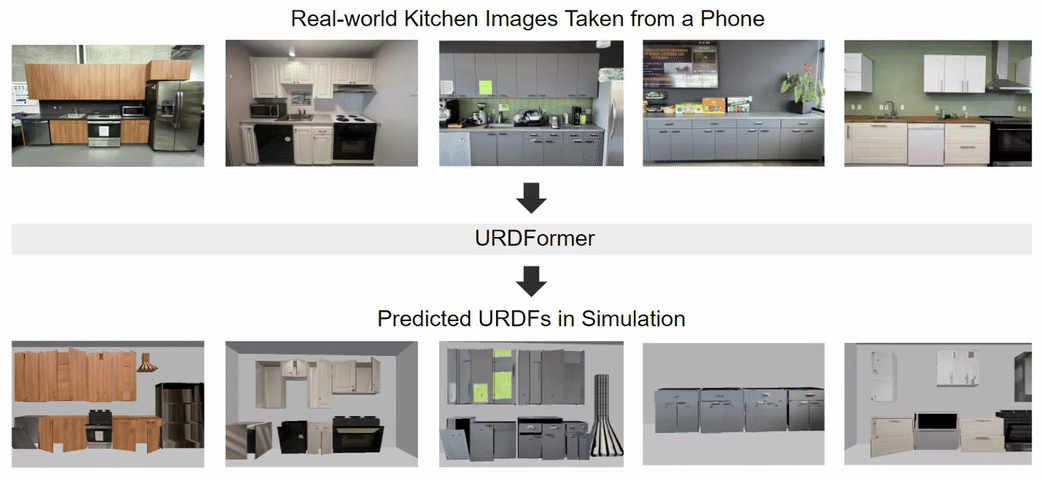
Constructing accurate and targeted simulation scenes that are both visually and physically realistic is a problem of significant practical interest in domains ranging from robotics to computer vision.
Achieving this goal since it provides a realistic, targeted simulation playground for training generalizable decision-making systems.
This problem has become even more relevant as researchers wielding large data-hungry learning methods seek new sources of training data for physical decision-making systems.
However, building simulation models is often still done by hand - a graphic designer and a simulation engineer work with predefined assets to construct rich scenes with realistic dynamic and kinematic properties.
While this may scale to small numbers of scenes, to achieve the generalization properties that are required for data-driven robotic control, we require a pipeline that is able to synthesize large numbers of realistic scenes,
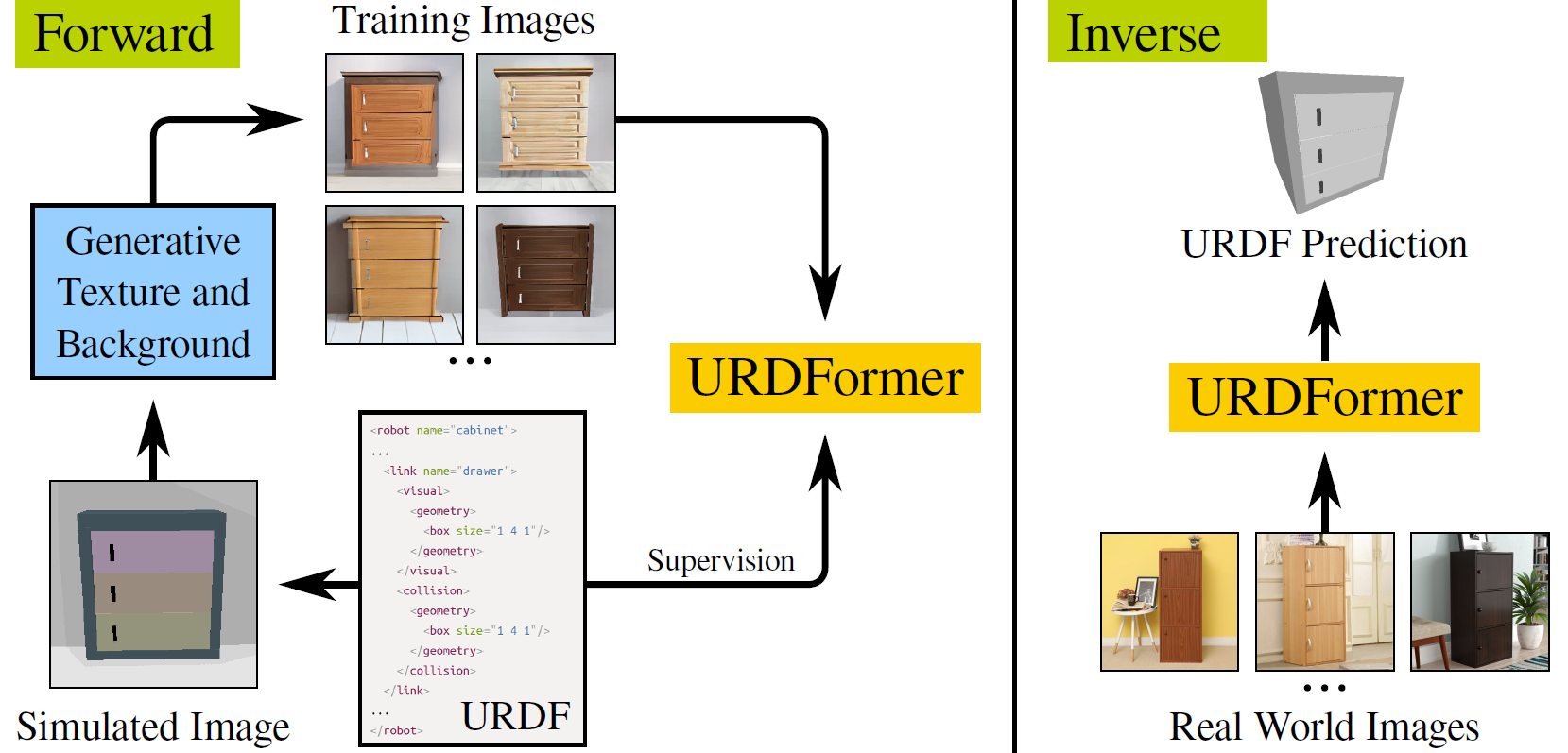
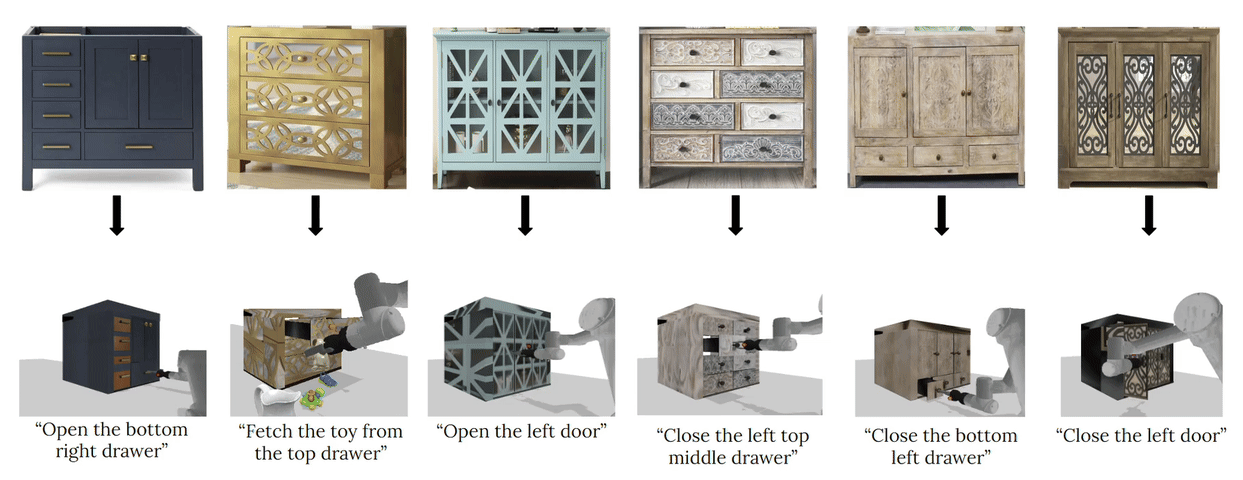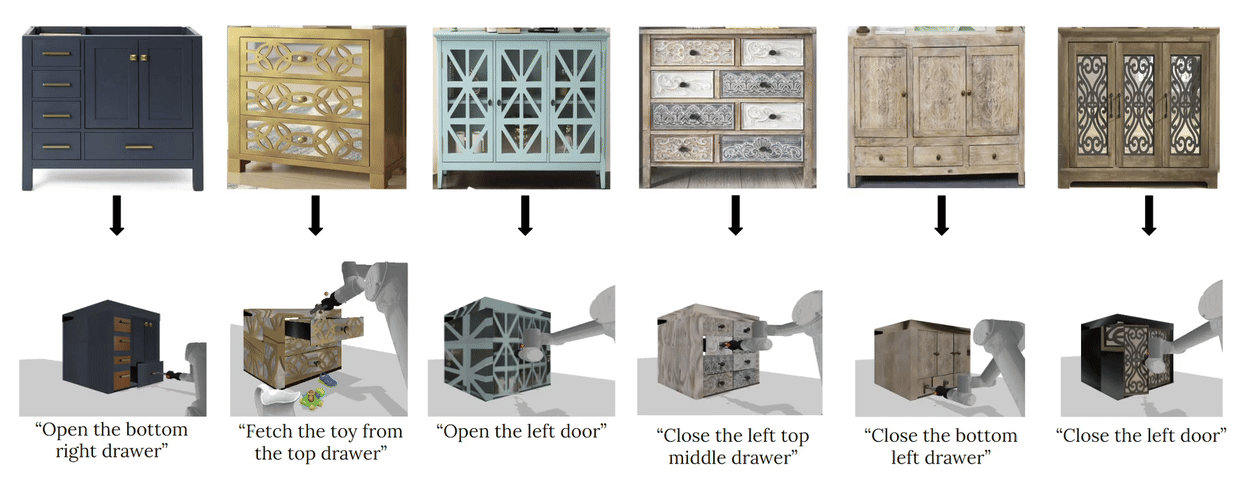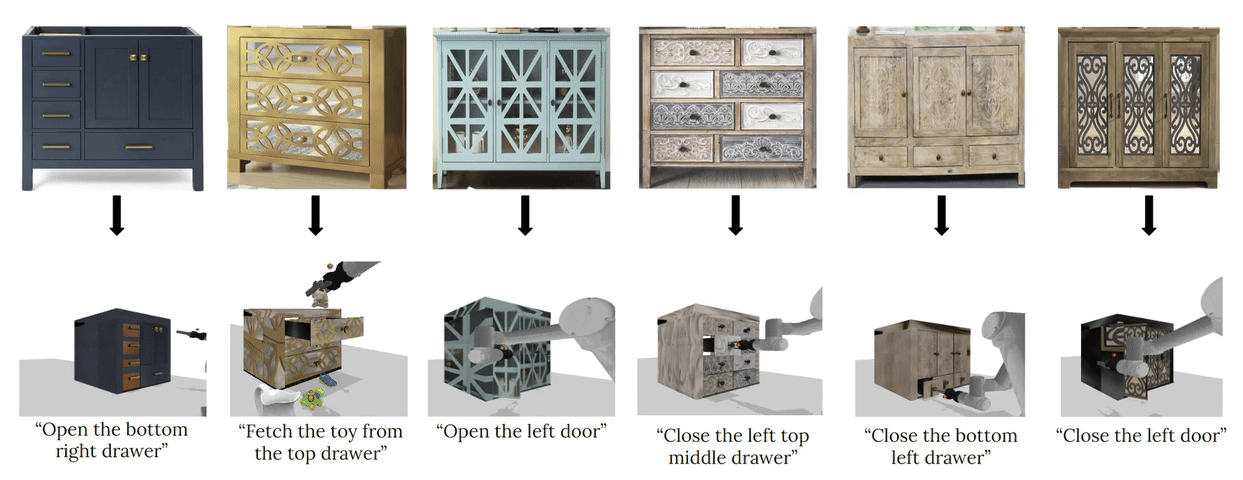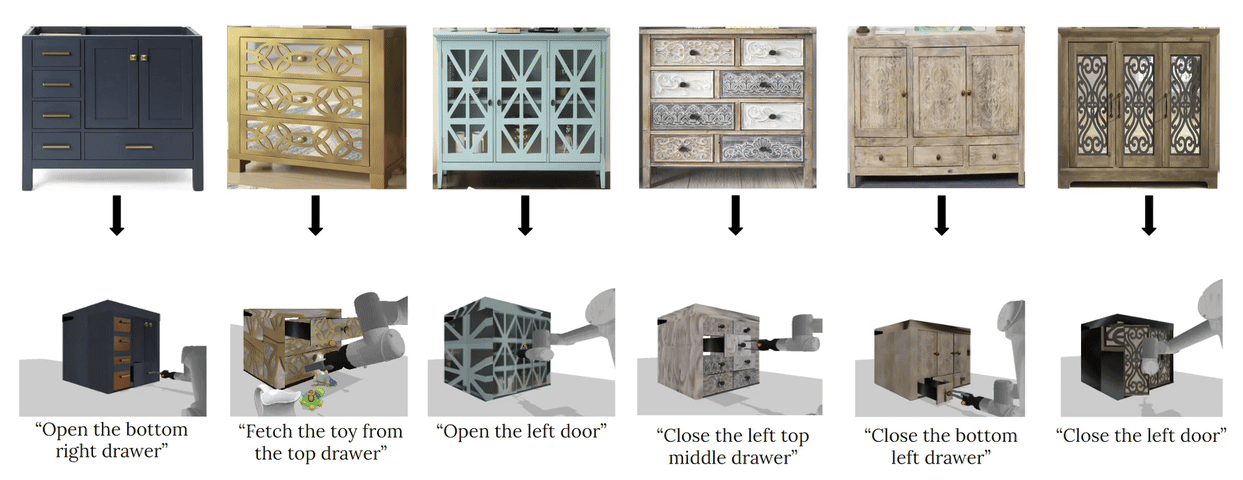
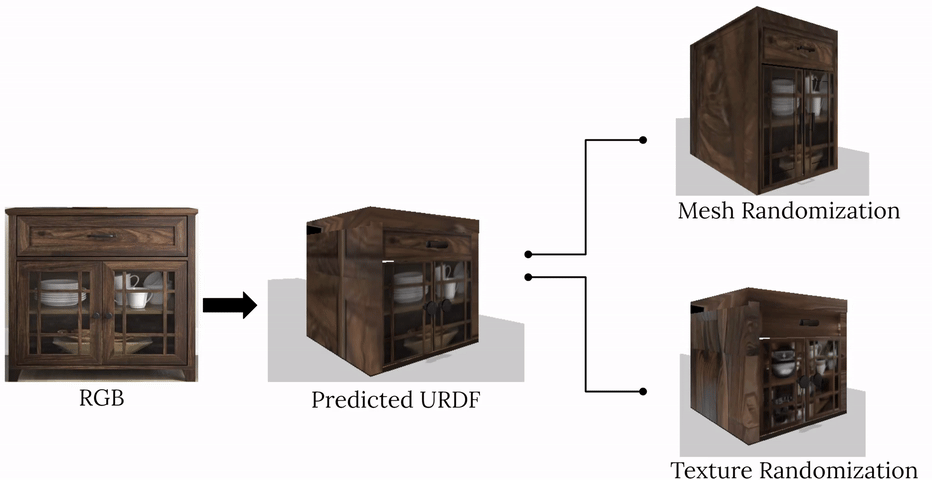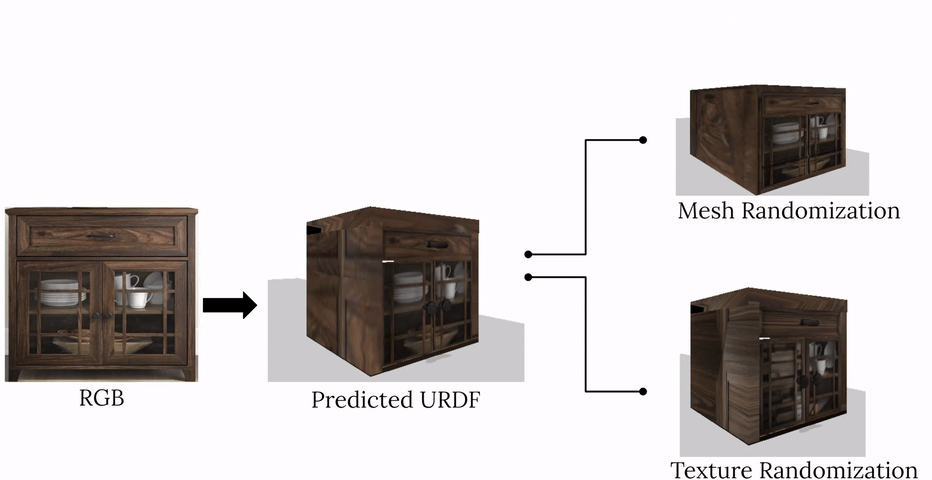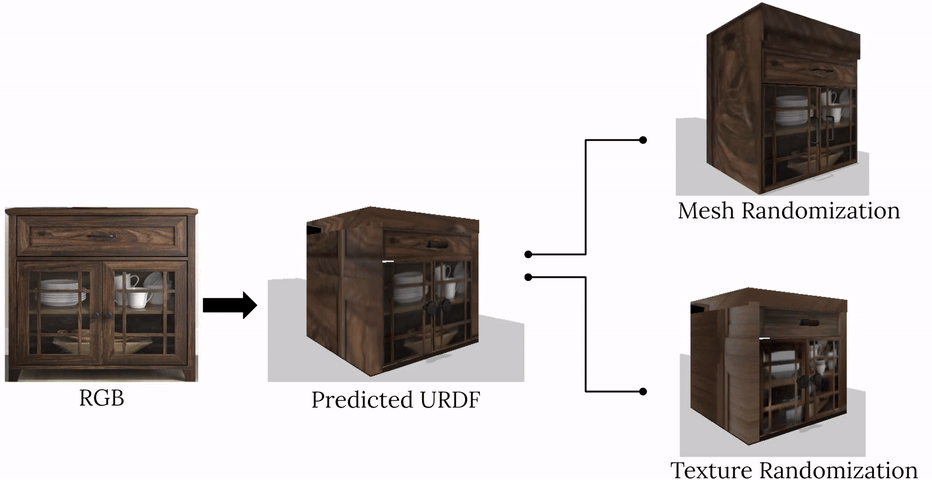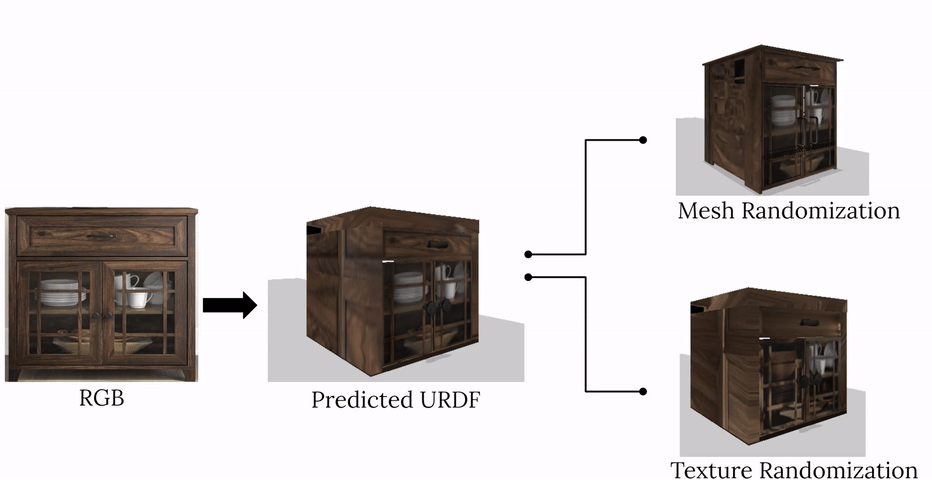
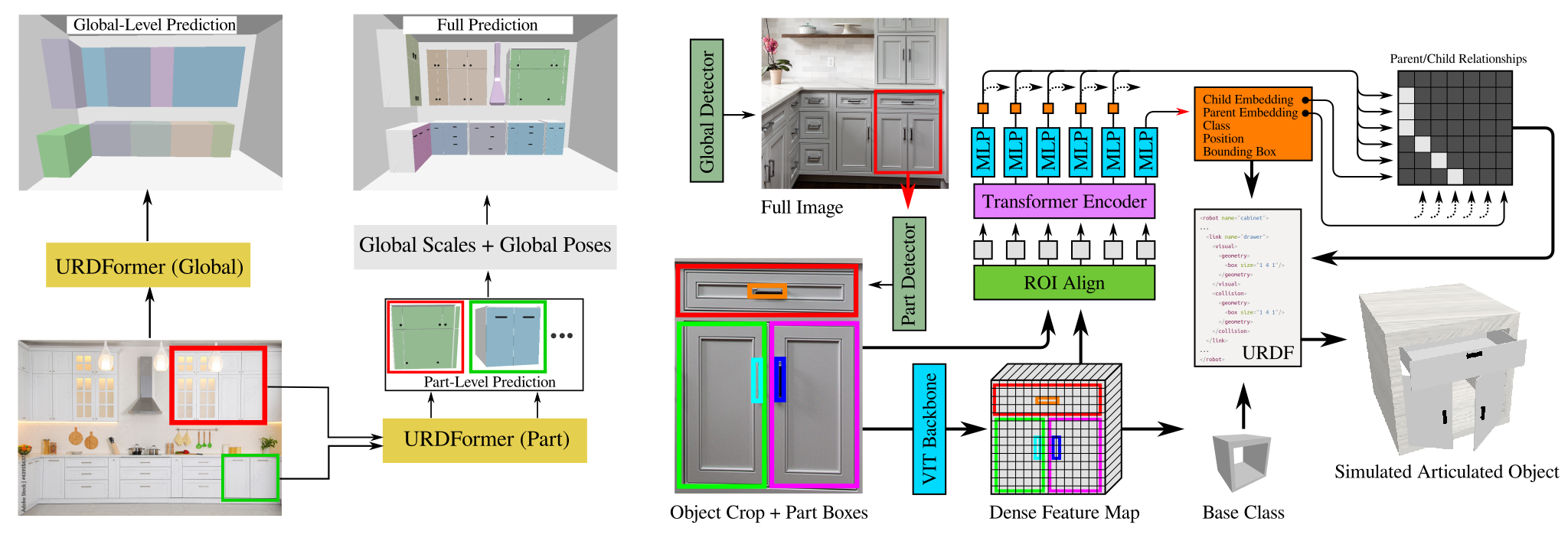
complete with ``natural" kinematic and dynamic structure. To attack this problem, we develop models for inferring structure and generating simulation scenes from natural images, allowing for scalable scene generation from web-scale datasets.
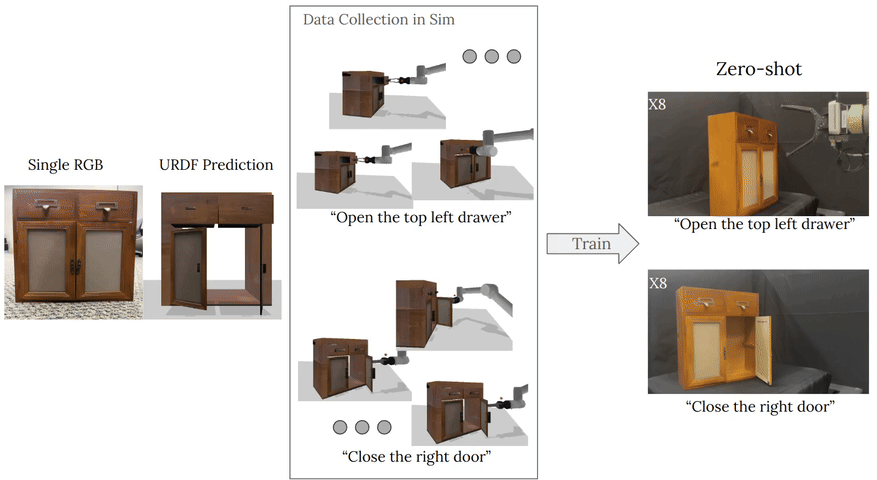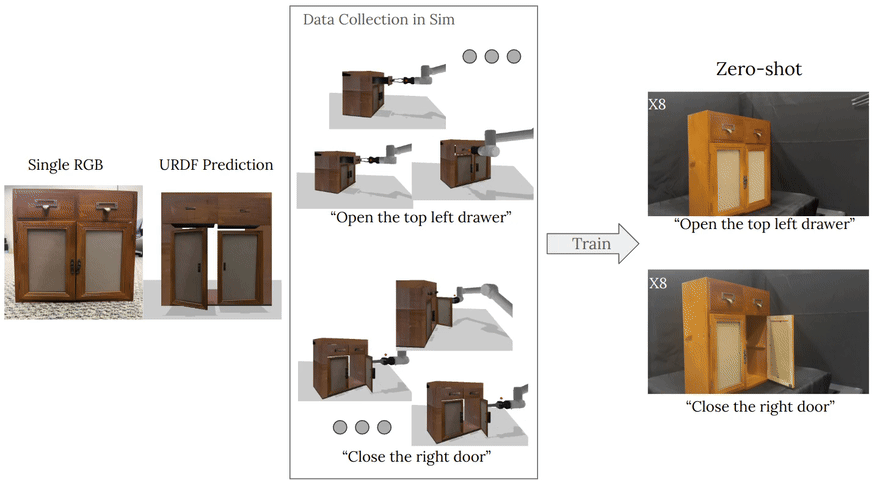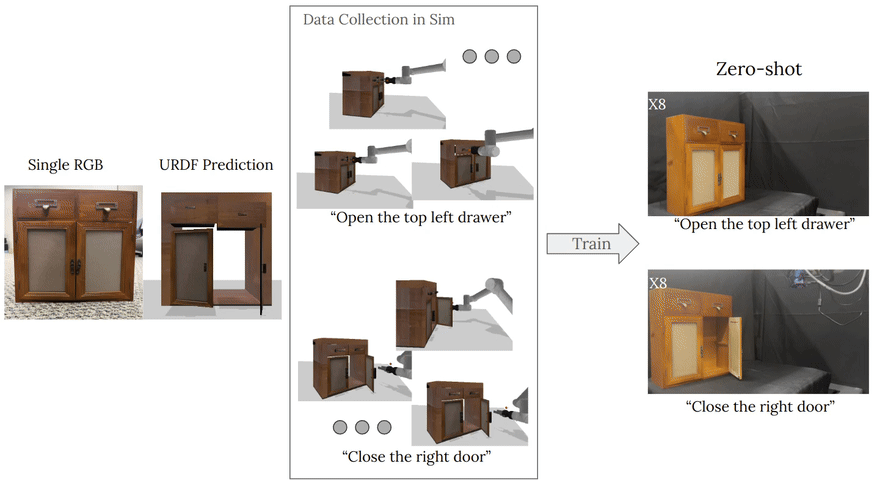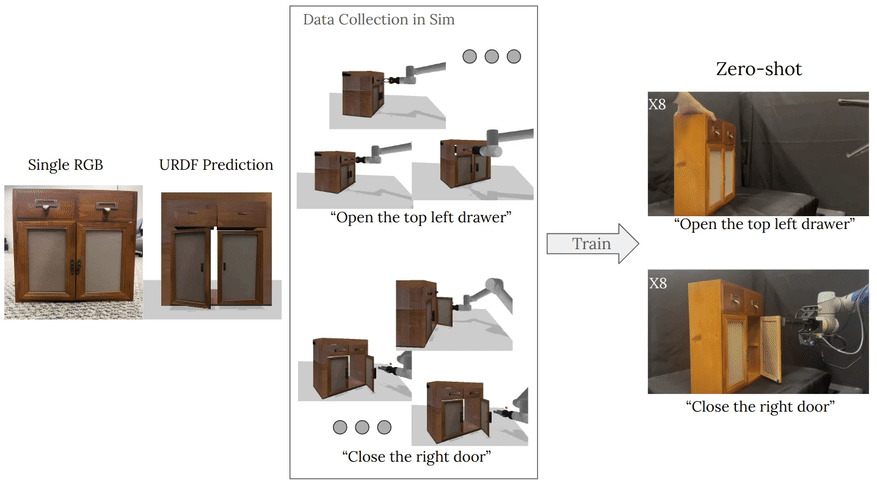
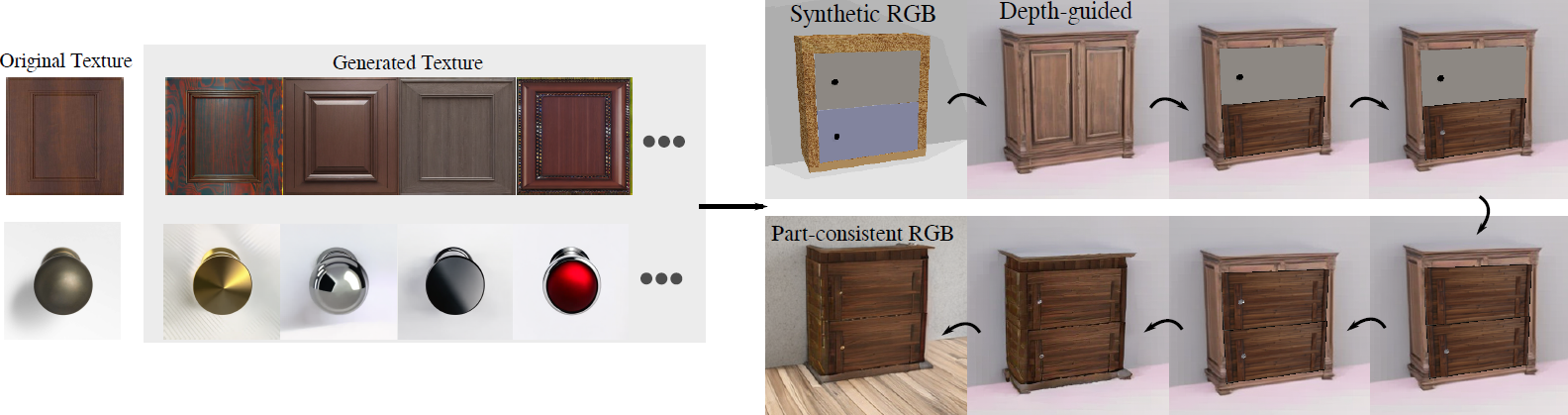
To train these image-to-simulation models, we show how controllable text-to-image generative models can be used in generating paired training data that allows for modeling of the inverse problem, mapping from realistic images back to complete scene models.
We show how this paradigm allows us to build large datasets of scenes in simulation with semantic and physical realism. We present an integrated end-to-end pipeline that generates simulation scenes complete with articulated kinematic and dynamic structures
from real-world images and use these for training robotic control policies. We then robustly deploy in the real world for tasks like articulated object manipulation. In doing so, our work provides both a pipeline for large-scale generation of simulation environments
and an integrated system for training robust robotic control policies in the resulting environments.